
Any time you find yourself with a data set with more than a few columns, say for example the 2012 Major League Baseball regular season stats sheet, you have a number of options when it comes to data exploration and discovery. The data set has all “qualifying” players, their team & position, and their number of games played, at bats, hits, homeruns, doubles, RBIs, etc. for the 2012 regular season. You can find the table online here.
Option #1: Table Madness
You could just sort and filter the table, and maybe even color-code the cells with some fancy conditional formatting in Excel (Home > Conditional Formatting > Color Scales > Red – White – Blue Color Scale). Interesting approach, but this doesn’t make use of the human brain’s superior capacity to make use of position or size to compare values. I’ll save it for all those dense quarterly financial spreadsheets. Here it is, for posterity:

Option #2: “O-F-A-T”
One option (called “O-F-A-T”, or “One Factor at a Time”) is to view each parameter, say, Homeruns, all by itself in a basic chart like a histogram. Rinse & repeat for all the other parameters. As nice as that is, you won’t really know anything about potential correlations between variables, you’ll just know each variable in isolation:

Option #3: Small Multiples
You could make a whole panel of histograms of each parameter, which would really just be a more efficient way of Option #2. Or, as demonstrated in Chapter 6 of Visualize This, you could plot each variable against each other variable in a scatterplot matrix (one form of small multiples chart). This option is preferred by many (created here using the R function “pairs()” which includes fitted LOESS curves), as it allows you to quickly scan for strong correlations between two variables (in this case, I reduced the number of variables in the matrix from 16 to 10 for readability):

A fairly quick scan shows that Homeruns and RBIs are fairly closely correlated in a positive sense (as are At bats and Runs). Can you spot the negative correlations? Not that hard to notice that Homeruns and Stolen Bases seem to be negatively correlated, right? To a fan of the game of baseball, none of these correlations will be particularly surprising, but the power in this approach is that many, many correlations can be identified, at least roughly speaking, in a very short amount of time. Do a quick Google Image search for “small multiples” and you’ll find other great examples of this powerful visualization. Here’s a recent piece by the New York Times showing drought conditions in the US since the late 19th century. Bottom line: I love small multiples.
Option #4: Interactive Visualizations
Lastly, you could create an interactive data discovery dashboard (created here using Tableau Public), using Parameters to allow the explorer of the data set to dynamically assign any of the 16 variables to the x-axis, the y-axis, the color palette or the circle size:
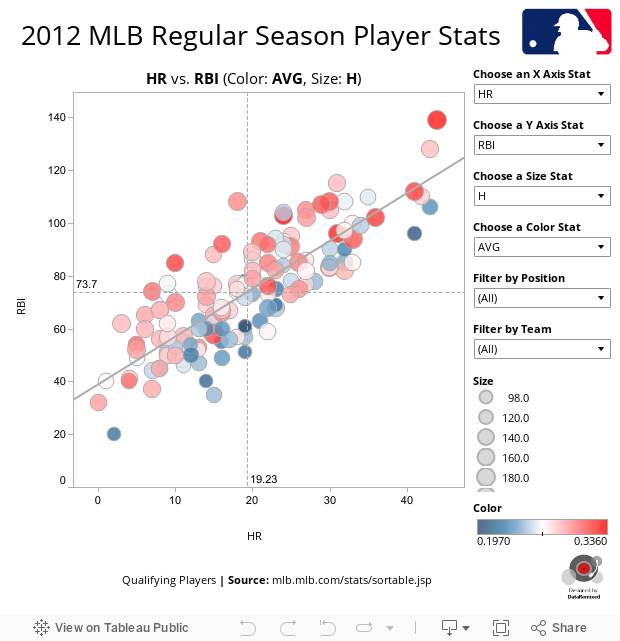
This effectively allows the user to compare any of the 4 parameters together. Of course, since position is more easy to discern than either color or area, the true comparison is still between the variable on the x-axis and the variable on the y-axis. Still, the other two variables are “along for the ride”, aiding a secondary analysis. The interactive environment also allows for the user to hover the mouse over any data point and learn more about the datum, or filter the view (in this case by either position or team).
So, Which Do You Prefer?
What I’d really like to know is: between Option #3 (small multiples) and Option #4 (interactive visualizations), which do you prefer, if any, and why? Do you prefer seeing it all at once at a high level, or do you want the ability to drill down, filter and customize a more limited but intricate view? Or are these totally different tools for totally different purposes that shouldn’t really be contrasted?
Thanks for stopping by!
Ben

Another option to reckon is the 3.5, which is made by opposing two interactive visualizations, so you can compare states (something that can be done in 3, with no little effort, and that 4 losses).
An evolved version of 4 would allow users to save states, so they can switch from one state to another, and thus compare (presumably the visualization will change continuously).
Finally, an interactive version of small multiples, in wich you can zoom, and also change parameters associated to axis, would be interesting.
I think the core of this article is that interaction could replace, in some cases, (static) visualization features. It would be interesting to make a list of cases like this one. I know another example, something I’ve used: using zoom to replace the use of a LOG scale in a scatter plot. But there are more.
Hi Santiago, t hanks for the comment. I’m intrigued – can you provide a link to a 3.5? I like the idea of a hybrid approach – multiple graphs with interaction included. So, not always and “either/or” but a case of using both.
Also, you’re reference to visualizations changing constantly – basically animated charts – is a great point and an option I didn’t include here but probably should have. I’ve seen this used very powerfully, especially when time is involved, such as in this video from Derek Watkins showing the expansion of US Post Offices.
Maybe I’m missing soetihmng, but is there really a need for Fusion Tables and Apps Script for this particular example? One could just use the built-in charts in Google Spreadsheets, right?I recognize that Fusion Tables has other charting options and apps script would give more flexibility in terms of automatically identifying the tossing out bad data, but the particular charts shown in this example just don’t scream the need for Fusion Tables in this application.
Hi Zanele, many thanks for the question – I actually didn’t use Google Fusion Tables, but would love to start using them more here. I used R for the small multiples scatterplot and Tableau Public for the interactive (“choose your own axes”) version. Is it overkill? Could be, though I find both incredibly easy to use, so there wasn’t much investment in time & energy to get it done.
I’d love to see your default Google Spreadsheets approach though. I’m all for the easiest approach that gets the job done, without a doubt.
Thanks again,
Ben
For me it’s no contest. The single scatter with the filters is the winner. Similar to the Archduke telling Mozart that there are only so many notes the human ear can hear in one setting, so too there are only so many ideas one can extract from a visualization at once. The consistent pattern of the colored dots against the regression makes the case, and encourages exploration and curiosity.
Hi Jon – thanks for the comment and I love the music analogy! The more I think about it the more it makes sense. The way I see it, most masterpieces are going to have both a symphony (lots of data at once, or small multiples) and a solo (focused view of the data, or interactive visualizations).
Just came across your blog. …
I’m also a fan of “3.5” or really 3+4 — combining a high-level view of correlations with an interactive tool to explore.
Click on the below link to see a a more use friendly correlation matrix:
http://bbmet-public.s3.amazonaws.com/MLB_Corrgram.png
I’ve only shown the “lower triangle” and ordered the correlations by strength.
This was generated with the R package corrgram:
library(“corrgram”)
corrgram(MLB2012_subset, order=TRUE, lower.panel=panel.shade, upper.panel=NULL, text.panel=panel.txt, main=”MLB Stat Correlations 2012″)
Very cool Jim, thanks for the info about the 3.5 chart – I like it, it definitely makes the correlations “pop”, even if it does leave out the texture of the data itself. I can see how this would be a good first step. Much appreciated!